This is my attempt at using Andy Matushak’s Orbit system to re-write the core readings from Week 2 of the AGI Safety Course organised by EA Cambridge.
Note that several paragraphs below are direct copies of the paragraphs in the original articles, but I have not made any indication when this is done. I realise this is in the strictest sense plagiarism, but the alternative is to break the flow by using quote blocks.
Introduction
Week 2 of the AGI Safety course focuses on ways in which AGI can be misaligned with humans. There are four core ideas.
First, it’s difficult to create reward functions which specify exactly what we want. This is known as the problem of “outer alignment”. Krakovna et al. (2020) at Deepmind discuss how outer misalignment can occur, giving some explicit examples.
Second, a reinforcement agent might pursue its own “inner objectives”, separate from the reward function. Ensuring that this inner objective is aligned with the original reward function is known as the problem of “inner alignment”. Hubinger et al. (2019a) explore inner alignment, explaining how a system might develop inner objectives that are misaligned with the reward function.
Third, Bostrom (2014) argues that almost all goals which an AGI might have would incentivise it to pursue various undesirable subgoals (e.g. self-preservation and resource acquisition), due to the phenomenon of “instrumental convergence”.
Fourth, and lastly, the above describe ways AI systems can be misaligned, but how do we define what it means for a system to be aligned? Christiano (2018) proposes the notion of “intent alignment” - an agent A is intent aligned with operator H if A is trying to do what H wants it to do.
Specification Gaming, by Krakovna et al. at Deepmind
Original article: https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-ingenuity
Specification gaming is a term coined by Krakovna et al. (abbreviated to ‘K.’) for behaviors that satisfy the literal specification of an objective without achieving the intended outcome. In AGI Safety, this is more commonly known as the problem of outer alignment: how can we specify objectives that will result in AGI doing what we want?
But why is this even a problem? As of April 2020, K. had collected around 60 examples of misalignment in AI systems (aggregating existing lists and ongoing contributions from the AI community). In the article, K. categorizes some of the reasons why misalignment occurs, giving explicit or hypothetical examples of each.
The three categories K. describe are:
- Misspecification of reward function
- Exploiting bugs in a simulator or our incorrect assumptions in a domain
- Reward tampering
Misspecification of the reward function
Example 1. In a Lego stacking task, the desired outcome was for a red block to end up on top of a blue block. The agent was rewarded for the height of the bottom face of the red block when it (the agent) is not touching the block. Instead of performing the relatively difficult maneuver of picking up the red block and placing it on top of the blue one, the agent simply flipped over the red block to collect the reward. This behavior achieved the stated objective (high bottom face of the red block) at the expense of what the designer actually cares about (stacking it on top of the blue one).

Source: Data-Efficient Deep Reinforcement Learning for Dexterous Manipulation (Popov et al, 2017)
Example 2. Consider an agent controlling a boat in the Coast Runners game, where the intended goal was to finish the boat race as quickly as possible. To help the agent learn the objective faster, the team gave the agent intermediate rewards on the way to completing the task - hitting green blocks along the race track - instead of only rewarding the final outcome. Introducing this intermediate reward changed the optimal policy, resulting in the agent going in circles and hitting the same green blocks over and over again:

Source: Faulty Reward Functions in the Wild (Amodei & Clark, 2016)
(Side note: introducing such intermediate rewards is called ‘reward shaping’ and the intention is to speed up learning. There are interesting and useful theoretical results about how one should define shaping rewards, e.g., they should be potential-based.)
Example 3. Instead of trying to create a reward function that covers every possible corner case, we could learn the reward function from human feedback. It is often easier to evaluate whether an outcome has been achieved than to specify it explicitly. Unfortunately, this is still prone to misalignment. For example, this directly optimizes for appearing to complete the task, which is correlated but not identical to completing the task. This has been observed when an agent performing a grasping task learned to fool the human evaluator by hovering between the camera and the object:
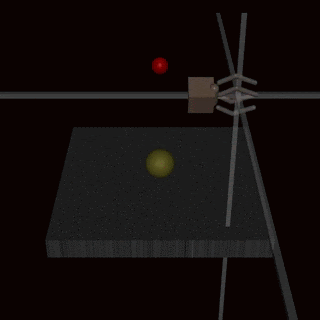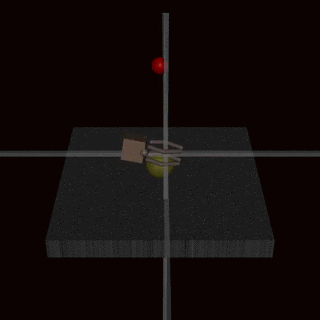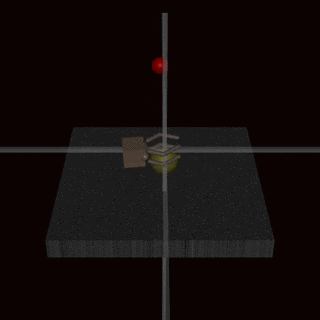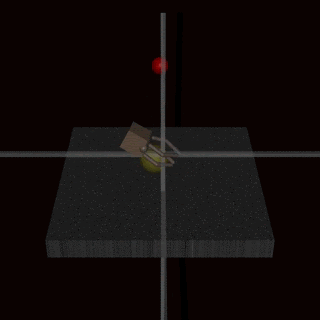
Source: Deep Reinforcement Learning From Human Preferences (Christiano et al, 2017)
Exploiting Bugs in a Simulator or Our Incorrect Assumptions
Another class of examples comes from the agent exploiting simulator bugs. For example, a simulated robot that was supposed to learn to walk figured out how to hook its legs together and slide along the ground:

Source: AI Learns to Walk (Code Bullet, 2019)
Such examples may seem amusing but irrelevant to deploying agents in the real world, where there are no simulator bugs. However, the underlying problem isn’t the bug itself but a failure of abstraction that can be exploited by the agent. In the example above, the robot’s task was misspecified because of incorrect assumptions about simulator physics. Analogously, a real-world traffic optimisation task might be misspecified by incorrectly assuming that the traffic routing infrastructure does not have software bugs or security vulnerabilities that a sufficiently clever agent could discover. Such assumptions need not be made explicitly – more likely, they are details that simply never occurred to the designer. And, as tasks grow too complex to consider every detail, researchers are more likely to introduce incorrect assumptions during specification design. This poses the question: is it possible to design agent architectures that correct for such false assumptions instead of gaming them?
Reward Tampering
One assumption commonly made is that the specification of the task cannot be affected by the agent’s actions. This is true for an agent running in a sandboxed simulator, but not for an agent acting in the real world. Any task specification has a physical manifestation: a reward function stored on a computer, or preferences stored in the head of a human. An agent deployed in the real world can potentially manipulate these representations of the objective, creating a reward tampering problem. For our hypothetical traffic optimisation system, there is no clear distinction between satisfying the user’s preferences (e.g. by giving useful directions), and influencing users to have preferences that are easier to satisfy (e.g. by nudging them to choose destinations that are easier to reach). The former satisfies the objective, while the latter manipulates the representation of the objective in the world (the user preferences), and both result in high reward for the AI system. As another, more extreme example, a very advanced AI system could hijack the computer on which it runs, manually setting its reward signal to a high value.
Risks from Learned Optimization, by Hubinger et al.
Original article: https://www.alignmentforum.org/posts/FkgsxrGf3QxhfLWHG/risks-from-learned-optimization-introduction
This article is the first of five posts in the Risks from Learned Optimization Sequence based on the paper “Risks from Learned Optimization in Advanced Machine Learning Systems” by Evan Hubinger, Chris van Merwijk, Vladimir Mikulik, Joar Skalse, and Scott Garrabrant. Each post in the sequence corresponds to a different section of the paper.
This first post introduces and defines key ideas (primarily mesa optimizers and inner alignment). The third post in the series (exploring how inner misalignment might occur) is part of extra reading for Week 2 and the fourth post in the series (on deceptive alignment) is a part of core reading for Week 3.
Optimizers
We say that a system is an optimizer if it is internally searching through a search space looking for those elements that score high according to some objective function that is explicitly represented within the system.
- Example: Gradient descent. For example, it is used to search through possible parameters of a neural network looking for those parameters that score low according to a loss function.
- Example: Chess engines. Chess engines search through thousands or millions of sequences of moves, evaluate the position after the moves, and then pick the best move based on these evaluations.
- Non-example: Endgame tablebase. The endgame tablebase contains the optimal move for all chess positions with 7 or fewer pieces. Thus, a chess engine (during such endgame) could follow the algorithm: look up the current position in the endgame tablebase and play the recommended move. This lookup involves no searching through a search space or evaluating of some objective function, so this is not an optimizer.
Whether a system is an optimizer is a property of its internal structure — what algorithm it is physically implementing — and not a property of its input-output behavior. Importantly, the fact that a system’s behavior results in some objective being maximized does not make the system an optimizer. For example, a chess engine that is searching through moves and evaluating is an optimizer whereas a chess engine that is just looking up moves in a database is not an optimizer.
An example used by Hubinger et al. is that a bottle cap is not an optimizer, despite the fact its ‘behavior’ does optimize the goal of keeping the liquid in a bottle. I personally dislike this example: a bottle cap is obviously not an optimizer and thinking about why does not seem enlightening. I hope the example of a chess engine following endgame tablebase is a better example!
Meta-optimizers
We say that an optimizer is a meta-optimizer if its search space is a space of optimizers. Phrased differently, a meta-optimizer is something that optimizes optimizers.
- Example: Hyper-parameter tuning for gradient descent. For example, an algorithm that tunes the optimal learning rate for gradient descent is a meta-optimizer. Its search space is a set of gradient descent algorithms and it is trying to find the ‘best’ one (e.g. the fastest to reach a certain accuracy).
- Non-example: Gradient descent on neural network image classifiers. Neural network image classifiers are not (generally) optimizers, so in this case, gradient descent is just an optimizer, not a meta-optimizer.
Mesa-optimizers
Suppose we have an optimizer that is not a meta-optimizer. For concreteness, imagine a gradient descent algorithm searching through neural network parameters. Most neural networks are not optimizers, but some neural networks are optimizers. (See footnote in original article for how this is possible.)
If such a neural network were produced in training by gradient descent, there would be two optimizers: the gradient descent algorithm that produced the neural network — which we will call the base optimizer — and the neural network itself — which we will call the mesa-optimizer.
To repeat: we use gradient descent on space of neural networks. Most of the time, the result of the search is a neural network that is not an optimizer. However, if the result is an optimizer, we call this resulting optimizer a mesa-optimizer.
This is a tricky concept, and many readers need more time and reflection to understand this concept than others in the AGI Safety Course. Please discuss and ask questions to check your understanding!
- Example (roughly): To a first approximation, evolution selects organisms according to the objective function of their inclusive genetic fitness in some environment. Most of these biological organisms (e.g. plants) are not “trying” to achieve anything, but instead merely implement heuristics that have been pre-selected by evolution. However, some organisms (e.g. humans) have behavior that is the result of goal-directed optimization algorithms implemented in their brains. In this example, evolution is the base optimizer and humans are a mesa-optimizer.
Base and Mesa Objectives
Suppose we have a base optimizer and a mesa-optimizer. Given our definition of optimizer, they each have some explicit objective they are trying to maximize, which we call the base objective and mesa objective.
- Example (roughly): Base optimizer is evolution and mesa optimizer is a human. Then the base objective is ‘genetic fitness in the particular environment’ whereas the mesa objective might be something like ‘maximize pleasure and minimize pain’.
Inner and Outer Alignment
Inner alignment is the problem of aligning the base objective with the mesa objective. This terminology is motivated by the fact that the inner alignment problem is an alignment problem entirely internal to the machine learning system, whereas the outer alignment problem is an alignment problem between the system and the humans outside of it (specifically between the base objective and the programmer’s intentions).
- Example (roughly): Base optimizer is evolution and mesa optimizer is a human. The objective function stored in the human brain is not perfectly aligned with the objective function of evolution. Making a decision not to have children is a possible example of this.
It might not be necessary to solve the inner alignment problem in order to produce safe, highly capable AI systems, as it might be possible to prevent mesa-optimizers from occurring in the first place. If mesa-optimizers cannot be reliably prevented, however, then some solution to both the outer and inner alignment problems will be necessary to ensure that mesa-optimizers are aligned with the intended goal of the programmers.
Robust Alignment and Pseudo-Alignment
Given enough training, a mesa-optimizer should eventually be able to produce outputs that score highly on the base objective on the training distribution. Off the training distribution, the difference could be arbitrarily large. We will use the term robustly aligned to refer to mesa-optimizers with mesa-objectives that robustly agree with the base objective across distributions and the term pseudo-aligned to refer to mesa-optimizers with mesa-objectives that agree with the base objective on past training data, but not robustly across possible future data (either in testing, deployment, or further training).
- Toy Example: Consider an RL agent trained on a maze navigation task where all the doors during training happen to be red. Let the base objective give a reward of 1 for reaching a door and 0 otherwise. Now suppose the trained RL agent is a mesa optimizer with the mesa objective ‘1 for reaching a red object and 0 otherwise’. This is a pseudo-aligned mesa optimizer: its objective is aligned with the base objective on the training set, but is clearly not aligned in general (imagine a maze with blue doors and red non-door objects).
One point worth emphasizing is that once a mesa-optimizer is deployed, only the mesa-objective has a (direct) influence on the behavior of the system, not the base objective. (This is analogous to the outer alignment problem, in which the objective function determines the behavior of the system, not the human intent).
Pseudo-Aligned Mesa-Optimizers as a Safety Problem
If pseudo-aligned mesa-optimizers may arise in advanced ML systems, as is argued in later posts in the sequence, they could pose two critical safety problems.
Unintended Optimization: First, the possibility of mesa-optimization means that an advanced ML system could end up implementing a powerful optimization procedure even if its programmers never intended it to do so. This could be dangerous if such optimization leads the system to take extremal actions outside the scope of its intended behavior in trying to maximize its mesa-objective. Of particular concern are optimizers with objective functions and optimization procedures that generalize to the real world.
Solving this likely involves preventing (or reducing the odds of) mesa-optimizers arising in the first place. The conditions that lead a learning algorithm to find mesa-optimizers, however, are very poorly understood. The second post in the sequences examines some features of machine learning algorithms that might influence their likelihood of finding mesa-optimizers.
Inner Alignment/Pseudo-Alignment: Second, the base objective and mesa objective could be misaligned. If so, the mesa-optimizer could produce bad behavior even if we had solved the outer alignment problem and chosen a good base objective. This bad behavior could happen either during training — before the mesa-optimizer is aligned on the training distribution — or during testing or deployment when the system is off the training distribution. The third post will address some ways in which a mesa-optimizer could be selected to optimize for something other than the base objective. In the fourth post, they discuss a possible extreme inner alignment failure — which they believe presents one of the most dangerous risks along these lines — wherein a sufficiently capable misaligned mesa-optimizer could learn to behave as if it were aligned without actually being robustly aligned. We will call this situation deceptive alignment.
It may be that pseudo-aligned mesa-optimizers are easy to address — if there exists a reliable method of aligning them, or of preventing base optimizers from finding them. However, it may also be that addressing misaligned mesa-optimizers is very difficult — the problem is not sufficiently well-understood at this point for us to know. Certainly, current ML systems do not produce dangerous mesa-optimizers, though whether future systems might is unknown. It is indeed because of these unknowns that we believe the problem is important to analyze.
Superintelligence, Chapter 7, by Bostrom
Original article: https://drive.google.com/file/d/1FVl9W2gW5_8ODYNZJ4nuFg79Z-_xkHkJ/view
Due to time restrictions, I was not able to re-write this article.
Clarifying AI Alignment, by Christiano
Original article: https://ai-alignment.com/clarifying-ai-alignment-cec47cd69dd6
Due to time restrictions, I was not able to re-write this article.